0. 개요
여러 Pytorch 에서 모델을 테스팅하기 위한 기본적인 틀을 정리해놓았다.
대부분의 경우 해당 틀에서 데이터 / 모델 내용 / 훈련 방법 만 바꾸면 된다.
- Import
- Hyperparameters Setting
- Preparing Data
- Model Structure
- Declare : Model, Loss, Optimizer
- Train (with validation) & Save
- Test
- Visualization & Analysis
Model Structure과 Train 부분은 워낙 구현 형태마다 다르니,
변수이름은 신경쓰지 말고 형식만 보기를 바란다.
1. Import
# torch
import torch
import torch.nn
import torch.nn.functional as F
import torch.nn.init as init
import torch.utils as utils
import torch.optim as optim
# torchvision
import torchvision.datasets as dset
import torchvision.transforms as transforms
# etc
import numpy as np
import matplotlib.pyplot as plt
자주쓰는 라이브러리들은 위와 같다.
다른 것 쓰면 더 넣으면 된다.
2. Hyperparameters Setting
# Hyperparameters Setting
epochs = 10
batch_size = 64
learning_rate = 1e-3
beta = (0.9, 0.999)
epsilon = 1e-10
pretrained_model_path = "./models/pretrained_model.pt"
save_model_path = "./models/"
save_result_path = "./results/"
is_gpu = True
num_gpu = 4
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")일반적으로 아래의 내용들을 세팅한다.
- Training 돌릴 epoch 수,
- 한번에 꺼내쓸 데이터량인 batch size,
- 학습량을 조절할 learning rate,
- Adam 등의 optimizer 사용시 필요한 계수 (이 경우 beta, epsilon)
- 모델과 결과물을 불러올/저장할 경로,
- gpu의 유무와 개수
3. Preparing Data
(1) dset에서 불러올 경우
# Transform Setting
composed = transforms.Compose([transforms.CenterCrop(10),
transforms.ToTensor()])
# Dataset Download
mnist_train = dset.MNIST("./", train=True, transform=composed, target_transform = None, download = True)
mnist_test = dset.MNIST("./", train=False, transform=composed, target_transform = None, download = True)
# Check
print(mnist_train.data.size())
print(mnist_train.targets.size())
# Data Loader
train_loader = utils.data.DataLoader(dataset = mnist_train, batch_size = batch_size, shuffle = True, drop_last = True)
test_loader = utils.data.DataLoader(dataset = mnist_test, batch_size = batch_size, shuffle = True, drop_last = True)
MNIST 예제다.
간단하다.
(2) 외부에서 가져올경우
somewhere
├─csv_file.csv
└─root_dir
├─img1.png
├─ ...
└─imgN.png// csv_file.csv
img1.png label1
img2.png label2
...
imgN.png labelN위와 같은 형식일 때
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
class DatasetSetting(Dataset):
def __init__(self, csv_file, root_dir, transform=None):
self.labels = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_name = os.path.join(self.root_dir,
self.labels.iloc[idx, 0])
image = io.imread(img_name)
label = self.labels.iloc[idx, 1:]
label = np.array([label])
label = label.astype('float').reshape(-1, 2)
sample = {'image': image, 'label': label}
if self.transform:
sample = self.transform(sample)
return sample
위와 같이 라벨이 들어있는 파일을 읽어 데이터셋을 가져오는 클래스를 만든 뒤
# Transform set
composed = transforms.Compose([transforms.CenterCrop(10),
transforms.ToTensor()])
# Dataset Load
dataset = DatasetSetting(csv_file_path, root_dir_path, composed)
# Check
import matplotlib.pyplot as plt
img, label = dataset.__getitem__(0)
plt.imshow(img)
print(label)
# Data Loader
data_loader = utils.data.DataLoader(dataset = dataset, batch_size = batch_size, shuffle = True, drop_last = True)MNIST를 불러올 때와 마찬가지로 하면 된다.
** 링크 로 가면 더 많은 Transform 종류를 볼 수 있다.
4. Model Structure
class Model1(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
...,
)
self.layer2 = nn.Sequential(OrderedDict([
('conv1', nn.ConvTranspose2d(256,128,3,2,1,1)), # [batch,256,7,7] -> [batch,128,14,14]
('bn1', nn.BatchNorm2d(128)),
('relu1', nn.ReLU()),
('conv2', nn.ConvTranspose2d(128,64,3,1,1)), # [batch,128,14,14] -> [batch,64,14,14]
('bn2', nn.BatchNorm2d(64)),
('relu2', nn.ReLU()),
]))
self.layer3 = nn.Sequential(OrderedDict([
...,
]))
self.init_size = (256,7,7)
def forward(self,z):
out = self.layer1(z)
out = out.view(batch_size//num_gpus, self.init_size[0], self.init_size[1], self.init_size[2])
out = self.layer2(out)
out = self.layer3(out)
return out
class Model2(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(OrderedDict([
...
]))
self.layer2 = nn.Sequential(OrderedDict([
...
]))
self.sigmoid = nn.Sigmoid()
def forward(self,x):
out = self.layer1(x)
out = out.view(batch_size//num_gpus, -1)
out = self.layer2(out)
output = self.sigmoid(out[:,0:1])
onehot = self.sigmoid(out[:,1:11])
c = out[:,11:]
return output,onehot,c위와 같이
nn.Module을 상속받은 class 를 만들어
__init__ 에는 레이어를,
forward 에는 input이 들어왔을 때 처리하는 구조를 만들어서
return 해주면 된다.
nn.Sequential을 쓸 땐 Model1처럼 OrderedDict를 이용해 이름을 붙여주면 좋다.
Model2 처럼 output이 label만이 아닌 경우도 존재한다.
5. Declare : Model, Loss, Optimizer
# models with multi GPU
model1 = nn.DataParallel(Model1(),device_ids=[0])
model2 = nn.DataParallel(Model2(),device_ids=[0])
# if there is no multi-gpus, below is enough to run.
# model1 = Model1()
try:
Model1, Model2 = torch.load(pretrained_model_path)
print("\n--------model restored--------\n")
except:
print("\n--------model not restored--------\n")
pass
# or initialize
# loss
model_loss = nn.BCELoss()
something_loss = nn.CrossEntropyLoss()
c_loss = nn.MSELoss()
# optimizer
model1_optim = torch.optim.Adam(model1.parameters(), lr = 5*learning_rate, betas = beta, eps = epsilon)
model2_optim = torch.optim.Adam(model2.parameters(), lr = learning_rate, betas = beta, eps = epsilon)(1) 모델 인스턴스 선언
그 뒤 미리 학습된 모델이 있다면 가져오고, 아니라면 initialize한다.
위 경우 zero initialize이기 때문에 별도의 선언을 하지 않았다.
(2) Loss 선언
구현할 논문 종류에 따라 loss의 개수가 달라지는데,
SRGAN의 경우 GAN_Loss, Categorical_Loss, Contin_Loss 의 세가지가 존재한다.
쉽게 말하자면, Loss의 개수는 꼭 model 개수와 일치하지는 않는다.
(3) Optimizer 선언
Hyperparameter를 세팅할 때 썼던 변수도 이 때 들어간다.
요즘은 묻따말(묻지도 따지지도 말고) Adam이다.
optimizer의 경우 model 개수와 일치하거나 더 적다.
위의 경우에도 learning rate를 일치시킨다면 아래와 같은 간단한 형태가 될 것이다.
optims = torch.optim.Adam(*list([model1.parameters(), model2.parameters()]), lr = learning_rate, betas = beta, eps = epsilon)
6. Train (with validation) & Save
for i in range(epochs):
for j, (inputs, label) in enumerate(data_loader):
inputs = inputs.cuda() # to use GPU
# gradient initialize
optims.zero_grad()
# preprocess input
inputs = asdfasdfasdfasdf
another_inputs = asdfasdfasdfasdf
# put through model and get model outputs
outputs1 = model1(inputs)
outputs2 = model2(another_inputs)
# compute loss
loss = torch.sum(model_loss(outputs1, label)
+ torch.sum(another_loss(outputs2, label))
+ torch.sum(c_loss(outputs1, output2))
# compute gradients of each parameters
loss.backward()
# optimize
optims.step()
# model save, output save
if j%10 == 0:
torch.save([model1, model2], os.path.join(save_model_path, 'pretrained_model.pt'))
print("epoch {} batch {} loss {}".format(i, j, loss.data))
v_utils.save_image(output1.data, os.path.join(save_result_path, "epoch{}batch{}.png".format(i, j), nrow=5))
# test with validation set if val_loader exist
if j%5 == 0:
with torch.no_grad():
val_loss = 0.0
for k, (val_inputs, val_label) in enumerate(val_loader):
val_output = model1(val_inputs)
...
v_loss = model_loss(val_output, val_label)
...
val_loss += v_loss
print("validation loss {}".format(val_loss))
Train 과정은 대체적으로 위와 같다.
epoch i의 mini-batch j에 대해
1) optimizer 의 gradient 초기화
2) input data를 preprocess (for 문 바깥에서 할 수 있다면 바깥에서 하는 게 더 좋음)
3) model에 input을 통과시켜 output을 구함
4) loss계산
5) backward propagation으로 gradient 계산
6) 계산한 gradient를 optimizer의 방법으로 parameter 계산
7) 필요시 모델 저장, 필요시 validation loss 계산
모델 저장과 validation loss 계산은 같이 하더라도 얼마든지 상관없다.
단, validation 계산시 with torch.no_grad():는 꼭 해주어야한다.
loss, validation loss같은경우 추후 visualization에서 분석할 때 많이 쓰므로 아래와 같이 append를 이용하기도 한다.
loss_history = []
val_loss_history = []
for i in range(epochs):
for j, (x, y) in enumerate(train_loader):
...
outputs = model(x)
loss = lossfunction(outputs,y)
loss_history.append(loss.data)
...
with torch.no_grad():
val_loss = 0.0
for k, (val_x, val_y) in enumerate(val_loader):
...
val_outputs = model(val_x)
v_loss = lossfunction(val_outputs, val_y)
val_loss += v_loss.data
...
val_loss_history.append(val_loss)
7. Test
(1) 1개 샘플 테스트
test loader를 준비했을 경우 아래와 같이 1개 샘플을 테스트 할 수 있다.
x, y = next(iter(test_loader)))
x = x.cuda()
out = model(x)
print(out.data[0], y[0])test loader가 없으면 OpenCV, PIL로 이미지를 불러오던지, f.read로 파일을 읽어오던지... 필요한대로 하면 된다.
(2) Test Loss 구하기
Loss 를 구하려면 Validation Loss를 구할 때 처럼 하면 된다.
with torch.no_grad():
test_loss = 0.0
for k, (test_inputs, test_label) in enumerate(val_loader):
test_output = model(test_inputs)
...
t_loss = lossfunction(test_output, test_label)
...
test_loss += t_loss
print("Test loss for batch {} : {}".format(k, test_loss))torch.no_grad()를 잊지 말자.
8. Visualization & Analysis
(1) Loss 보기
x_loss = np.reshape([i for i in range(epochs)], newshape=[epochs, 1])
train_loss_data = np.reshape(loss_history, newshape=[epochs,1])
validation_loss_data = np.reshape(val_loss_history, newshape=[epochs,1])
fig = plt.figure()
plt.plot(x_loss,train_loss_data, 'r')
plt.plot(x_loss, validation_loss_data, 'b')
plt.show()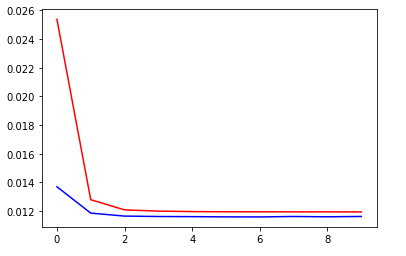
Loss를 Visualize하는 방법이다.
Train 시 미리 History를 만들어놓아야 한다.
(2) Output 보기
GAN의 경우 아래와 같이 결과물을 볼 수도 있다.
x, _ = next(iter(test_loader))
x = x.cuda()
x_recon = model(x)
fig = plt.figure(figsize=(2,2*batch_size))
for i in range(batch_size):
plt.subplot(batch_size,2,2*i+1)
plt.imshow(torch.squeeze(x.data[i].cpu(), dim=0).numpy())
plt.subplot(batch_size,2,2*i+2)
plt.imshow(torch.squeeze(x_recon.data[i].cpu(), dim=0).numpy())
plt.show()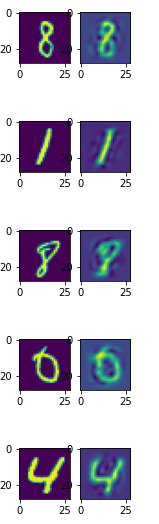
꼭 GAN의 plt.imshow 가 아니더라도,
Classification 문제에서 one-hot encoding해서 결과물을 본다던지 하면 된다.
다음에 따로 정리해야지.
'SW > DeepLearning' 카테고리의 다른 글
| [Deep Learning] L1 Regularization의 Gradient에 관한 소고 (0) | 2020.07.02 |
|---|---|
| [PyTorch] PyTorch Basic - Data Handling (0) | 2020.06.27 |
| [Pytorch] Pytorch로 ResNet bottleneck 만들기 (0) | 2020.06.27 |

